
Libraries are collections of code that are intended to be usable by multiple consumers (if you're interested in the etymology, watch
this video). In the old days we had what we now refer to as "static" libraries, collections of code that existed on disk but which would be copied into newly compiled binaries. We've moved beyond that, thankfully, and now make use of what we call "dynamic" or "shared" libraries - instead of the code being copied into the binary, a reference to the library function is incorporated, and at runtime the code is mapped from the on-disk copy of the shared object[1]. This allows libraries to be upgraded without needing to modify the binaries using them, and if multiple applications are using the same library at once it only requires that one copy of the code be kept in RAM.
But for this to work, two things are necessary: when we build a binary, there has to be a way to reference the relevant library functions in the binary; and when we run a binary, the library code needs to be mapped into the process.
(I'm going to somewhat simplify the explanations from here on - things like symbol versioning make this a bit more complicated but aren't strictly relevant to what I was working on here)
For the first of these, the goal is to replace a call to a function (eg,
printf()) with a reference to the actual implementation. This is the job of the linker rather than the compiler (eg, if you use the
-c argument to tell gcc to simply compile to an object rather than linking an executable, it's not going to care about whether or not every function called in your code actually exists or not - that'll be figured out when you link all the objects together), and the linker needs to know which symbols (which aren't just functions - libraries can export variables or structures and so on) are available in which libraries. You give the linker a list of libraries, it extracts the symbols available, and resolves the references in your code with references to the library.
But how is that information extracted? Each ELF object has a fixed-size header that contains references to various things, including a reference to a list of "section headers". Each section has a name and a type, but the ones we're interested in are
.dynstr and
.dynsym.
.dynstr contains a list of strings, representing the name of each exported symbol.
.dynsym is where things get more interesting - it's a list of structs that contain information about each symbol. This includes a bunch of fairly complicated stuff that you need to care about if you're actually writing a linker, but the relevant entries for this discussion are an index into
.dynstr (which means the
.dynsym entry isn't sufficient to know the name of a symbol, you need to extract that from
.dynstr), along with the location of that symbol within the library. The linker can parse this information and obtain a list of symbol names and addresses, and can now replace the call to
printf() with a reference to libc instead.
(Note that it's not possible to simply encode this as "Call this address in this library" - if the library is rebuilt or is a different version, the function could move to a different location)
Experimentally,
.dynstr and
.dynsym appear to be sufficient for linking a dynamic library at build time - there are other sections related to dynamic linking, but you can link against a library that's missing them. Runtime is where things get more complicated.
When you run a binary that makes use of dynamic libraries, the code from those libraries needs to be mapped into the resulting process. This is the job of the runtime dynamic linker, or RTLD[2]. The RTLD needs to open every library the process requires, map the relevant code into the process's address space, and then rewrite the references in the binary into calls to the library code. This requires more information than is present in
.dynstr and
.dynsym - at the very least, it needs to know the list of required libraries.
There's a separate section called
.dynamic that contains another list of structures, and it's the data here that's used for this purpose. For example,
.dynamic contains a bunch of entries of type
DT_NEEDED - this is the list of libraries that an executable requires. There's also a bunch of other stuff that's required to actually make all of this work, but the only thing I'm going to touch on is
DT_HASH. Doing all this re-linking at runtime involves resolving the locations of a large number of symbols, and if the only way you can do that is by reading a list from
.dynsym and then looking up every name in
.dynstr that's going to take some time. The
DT_HASH entry points to a hash table - the RTLD hashes the symbol name it's trying to resolve, looks it up in that hash table, and gets the symbol entry directly (it still needs to resolve that against
.dynstr to make sure it hasn't hit a hash collision - if it has it needs to look up the next hash entry, but this is still generally faster than walking the entire
.dynsym list to find the relevant symbol). There's also
DT_GNU_HASH which fulfills the same purpose as
DT_HASH but uses a more complicated algorithm that performs even better.
.dynamic also contains entries pointing at
.dynstr and
.dynsym, which seems redundant but will become relevant shortly.
So,
.dynsym and
.dynstr are required at build time, and both are required along with
.dynamic at runtime. This seems simple enough, but obviously there's a twist and I'm sorry it's taken so long to get to this point.
I bought a
Synology NAS for home backup purposes (my previous solution was a single external USB drive plugged into a small server, which had uncomfortable single point of failure properties). Obviously I decided to poke around at it, and I found something odd - all the libraries Synology ships were entirely lacking any ELF section headers. This meant no
.dynstr,
.dynsym or
.dynamic sections, so how was any of this working?
nm asserted that the libraries exported no symbols, and
readelf agreed. If I wrote a small app that called a function in one of the libraries and built it,
gcc complained that the function was undefined. But executables on the device were clearly resolving the symbols at runtime, and if I loaded them into
ghidra the exported functions were visible. If I
dlopen()ed them,
dlsym() couldn't resolve the symbols - but if I hardcoded the offset into my code, I could call them directly.
Things finally made sense when I discovered that if I passed the
--use-dynamic argument to
readelf, I
did get a list of exported symbols. It turns out that ELF is weirder than I realised. As well as the aforementioned section headers, ELF objects also include a set of program headers. One of the program header types is
PT_DYNAMIC. This typically points to the same data that's present in the
.dynamic section. Remember when I mentioned that
.dynamic contained references to
.dynsym and
.dynstr? This means that simply pointing at
.dynamic is sufficient, there's no need to have separate entries for them.
The same information can be reached from two different locations. The information in the section headers is used at build time, and the information in the program headers at run time[3]. I do not have an explanation for this. But if the information is present in two places, it seems obvious that it should be able to reconstruct the missing section headers in my weird libraries? So that's what
this does. It extracts information from the
DYNAMIC entry in the program headers and creates equivalent section headers.
There's one thing that makes this more difficult than it might seem. The section header for
.dynsym has to contain the number of symbols present in the section. And that information doesn't directly exist in
DYNAMIC - to figure out how many symbols exist, you're expected to walk the hash tables and keep track of the largest number you've seen. Since every symbol has to be referenced in the hash table, once you've hit every entry the largest number is the number of exported symbols. This seemed annoying to implement, so instead I cheated, added code to simply pass in the number of symbols on the command line, and then just parsed the output of
readelf against the original binaries to extract that information and pass it to my tool.
Somehow, this worked. I now have a bunch of library files that I can link into my own binaries to make it easier to figure out how various things on the Synology work. Now, could someone explain (a) why this information is present in two locations, and (b) why the build-time linker and run-time linker disagree on the canonical source of truth?
[1] "Shared object" is the source of the .so filename extension used in various Unix-style operating systems
[2] You'll note that "RTLD" is not an acryonym for "runtime dynamic linker", because reasons
[3] For environments using the GNU RTLD, at least - I have no idea whether this is the case in all ELF environments

comments
 After seven years of service as member and secretary on the GHC Steering Committee, I have resigned from that role. So this is a good time to look back and retrace the formation of the GHC proposal process and committee.
In my memory, I helped define and shape the proposal process, optimizing it for effectiveness and throughput, but memory can be misleading, and judging from the paper trail in my email archives, this was indeed mostly Ben Gamari s and Richard Eisenberg s achievement: Already in Summer of 2016, Ben Gamari set up the ghc-proposals Github repository with a sketch of a process and sent out a call for nominations on the GHC user s mailing list, which I replied to. The Simons picked the first set of members, and in the fall of 2016 we discussed the committee s by-laws and procedures. As so often, Richard was an influential shaping force here.
After seven years of service as member and secretary on the GHC Steering Committee, I have resigned from that role. So this is a good time to look back and retrace the formation of the GHC proposal process and committee.
In my memory, I helped define and shape the proposal process, optimizing it for effectiveness and throughput, but memory can be misleading, and judging from the paper trail in my email archives, this was indeed mostly Ben Gamari s and Richard Eisenberg s achievement: Already in Summer of 2016, Ben Gamari set up the ghc-proposals Github repository with a sketch of a process and sent out a call for nominations on the GHC user s mailing list, which I replied to. The Simons picked the first set of members, and in the fall of 2016 we discussed the committee s by-laws and procedures. As so often, Richard was an influential shaping force here.
 After more than one a year, a new minor FAI version is available, but
it includes some interesting new features.
Here a the items from the NEWS file:
fai (6.2) unstable; urgency=low
After more than one a year, a new minor FAI version is available, but
it includes some interesting new features.
Here a the items from the NEWS file:
fai (6.2) unstable; urgency=low

 A very minor maintenance release, now at version 0.0.22, of
A very minor maintenance release, now at version 0.0.22, of  Now that I m
Now that I m 

 I can t actually think of a meme with this GIF, that the internal
I can t actually think of a meme with this GIF, that the internal  I think while developing Wayland-as-an-ecosystem we are now entrenched into narrow concepts of how a desktop should work. While discussing Wayland protocol additions, a lot of concepts clash, people from different desktops with different design philosophies debate the merits of those over and over again never reaching any conclusion (just as you will never get an answer out of humans whether sushi or pizza is the clearly superior food, or whether CSD or SSD is better). Some people want to use Wayland as a vehicle to force applications to submit to their desktop s design philosophies, others prefer the smallest and leanest protocol possible, other developers want the most elegant behavior possible. To be clear, I think those are all very valid approaches.
But this also creates problems: By switching to Wayland compositors, we are already forcing a lot of porting work onto toolkit developers and application developers. This is annoying, but just work that has to be done. It becomes frustrating though if Wayland provides toolkits with absolutely no way to reach their goal in any reasonable way. For Nate s Photoshop analogy: Of course Linux does not break Photoshop, it is Adobe s responsibility to port it. But what if Linux was missing a crucial syscall that Photoshop needed for proper functionality and Adobe couldn t port it without that? In that case it becomes much less clear on who is to blame for Photoshop not being available.
A lot of Wayland protocol work is focused on the environment and design, while applications and work to port them often is considered less. I think this happens because the overlap between application developers and developers of the desktop environments is not necessarily large, and the overlap with people willing to engage with Wayland upstream is even smaller. The combination of Windows developers porting apps to Linux and having involvement with toolkits or Wayland is pretty much nonexistent. So they have less of a voice.
I think while developing Wayland-as-an-ecosystem we are now entrenched into narrow concepts of how a desktop should work. While discussing Wayland protocol additions, a lot of concepts clash, people from different desktops with different design philosophies debate the merits of those over and over again never reaching any conclusion (just as you will never get an answer out of humans whether sushi or pizza is the clearly superior food, or whether CSD or SSD is better). Some people want to use Wayland as a vehicle to force applications to submit to their desktop s design philosophies, others prefer the smallest and leanest protocol possible, other developers want the most elegant behavior possible. To be clear, I think those are all very valid approaches.
But this also creates problems: By switching to Wayland compositors, we are already forcing a lot of porting work onto toolkit developers and application developers. This is annoying, but just work that has to be done. It becomes frustrating though if Wayland provides toolkits with absolutely no way to reach their goal in any reasonable way. For Nate s Photoshop analogy: Of course Linux does not break Photoshop, it is Adobe s responsibility to port it. But what if Linux was missing a crucial syscall that Photoshop needed for proper functionality and Adobe couldn t port it without that? In that case it becomes much less clear on who is to blame for Photoshop not being available.
A lot of Wayland protocol work is focused on the environment and design, while applications and work to port them often is considered less. I think this happens because the overlap between application developers and developers of the desktop environments is not necessarily large, and the overlap with people willing to engage with Wayland upstream is even smaller. The combination of Windows developers porting apps to Linux and having involvement with toolkits or Wayland is pretty much nonexistent. So they have less of a voice.

 I will also bring my two protocol MRs to their conclusion for sure, because as application developers we need clarity on what the platform (either all desktops or even just a few) supports and will or will not support in future. And the only way to get something good done is by contribution and friendly discussion.
I will also bring my two protocol MRs to their conclusion for sure, because as application developers we need clarity on what the platform (either all desktops or even just a few) supports and will or will not support in future. And the only way to get something good done is by contribution and friendly discussion.


 Now copy the ISO image to the newly created instance and extract
its data:
Now copy the ISO image to the newly created instance and extract
its data:
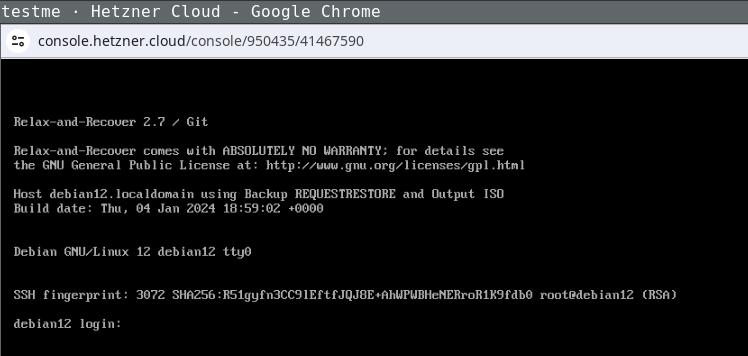 Login the recovery console (root without password) and fix its default route to
make it reachable:
Login the recovery console (root without password) and fix its default route to
make it reachable:
 Being able to use this procedure for complete disaster recovery within Hetzner
cloud VPS (using off-site backups) gives me a better feeling, too.
Being able to use this procedure for complete disaster recovery within Hetzner
cloud VPS (using off-site backups) gives me a better feeling, too.
 Figure 1: Content-Security-Policy browser communication
This is revolutionary, because it allows servers to receive feedback
in real time on errors that may be appearing in the browser s console.
Figure 1: Content-Security-Policy browser communication
This is revolutionary, because it allows servers to receive feedback
in real time on errors that may be appearing in the browser s console.



 Read all parts of the series
Read all parts of the series
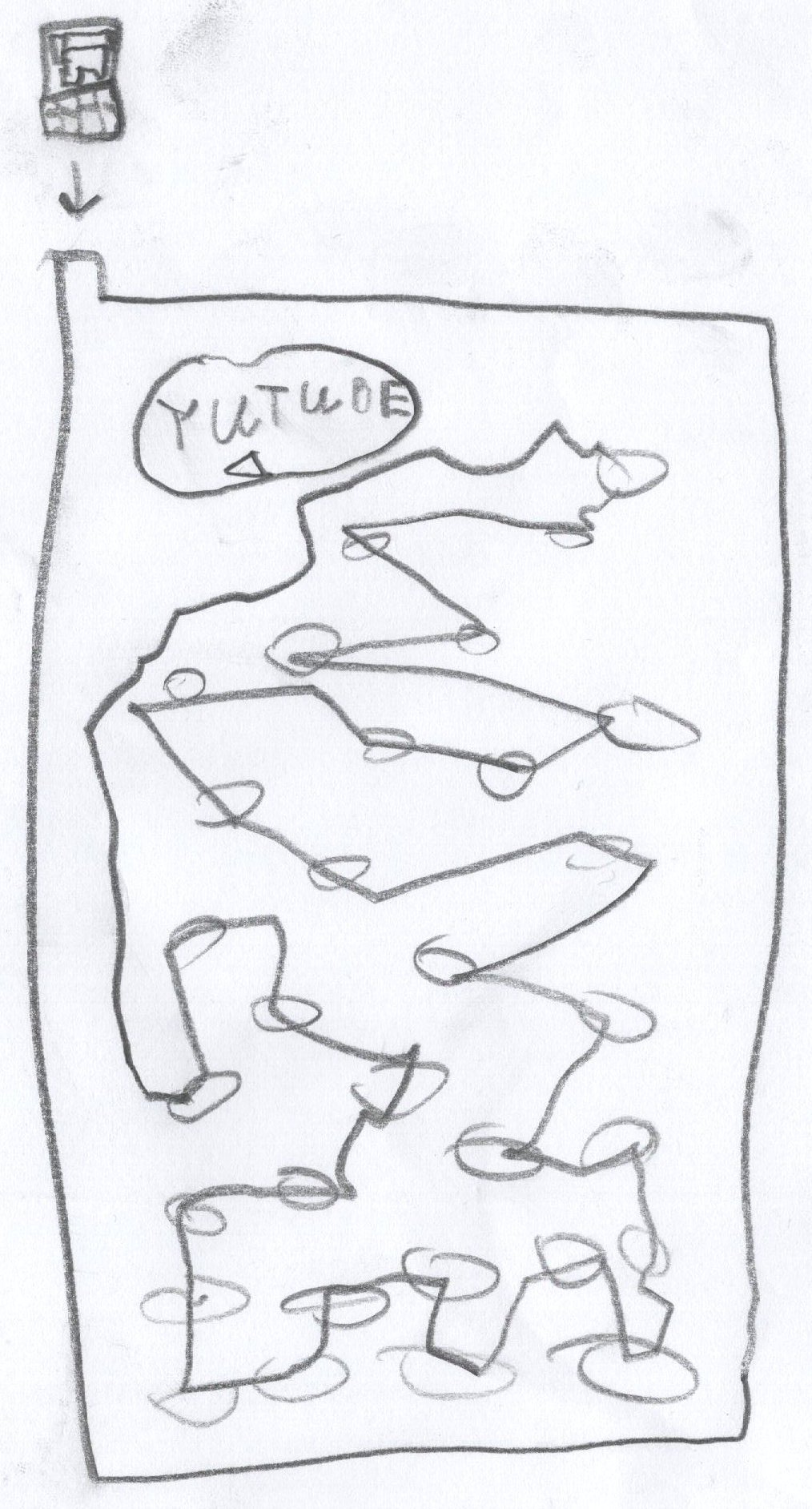
 And here s what he explains about his drawing:
And here s what he explains about his drawing:
 In their drawing we see a Youtube prank channel on a screen, an external
trackpad on the right (likely it s not a touch screen), and headphones.
Notice how there is no keyboard, or maybe it s folded away.
If you could ask a nice and friendly dragon anything you d like to
learn about the internet, what would it be?
In their drawing we see a Youtube prank channel on a screen, an external
trackpad on the right (likely it s not a touch screen), and headphones.
Notice how there is no keyboard, or maybe it s folded away.
If you could ask a nice and friendly dragon anything you d like to
learn about the internet, what would it be?
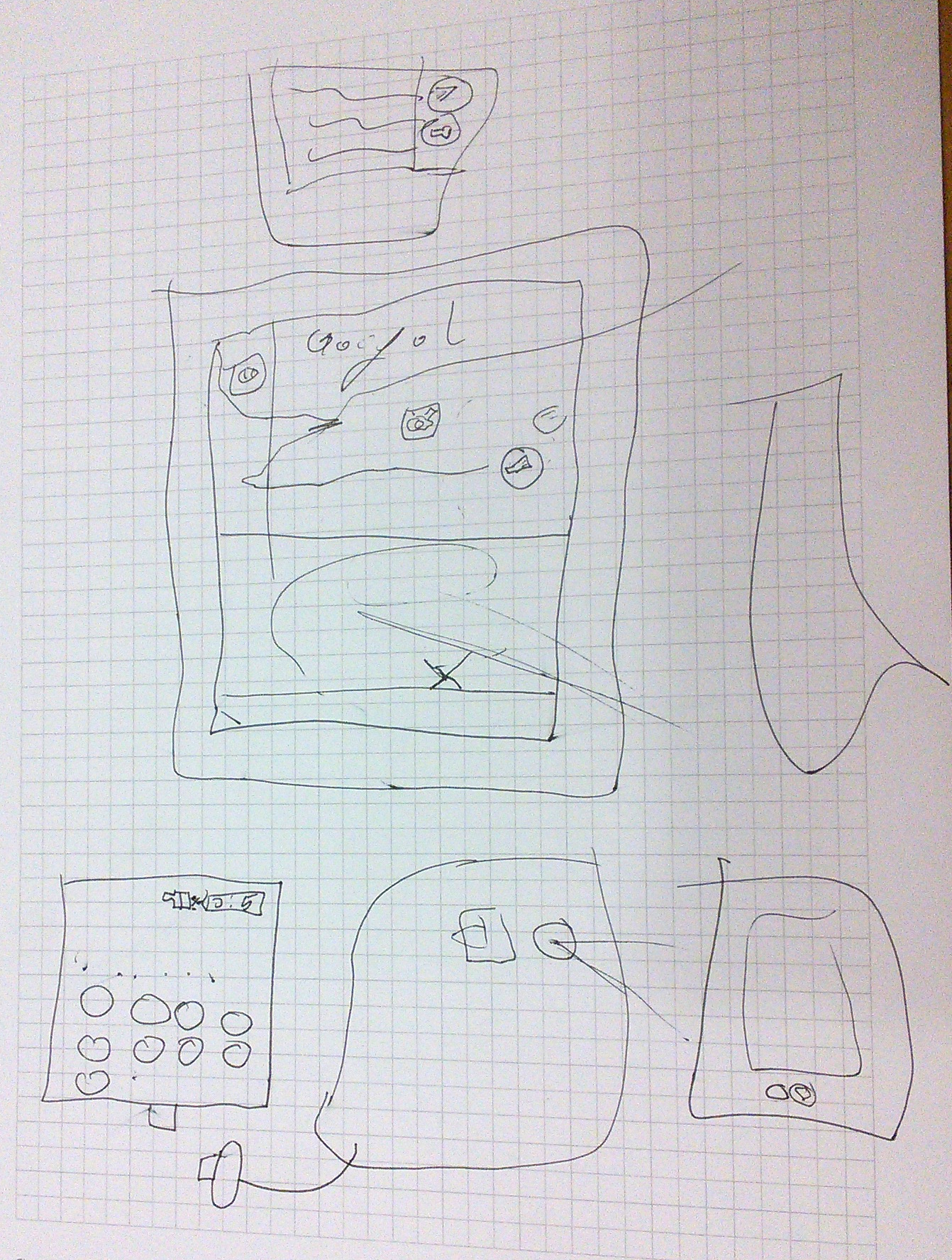 In her drawing, we see again Google - it s clearly everywhere - and also
the interfaces for calling and texting someone.
To explain what the internet is, besides the fact that one
can use it for calling and listening to music, she says:
In her drawing, we see again Google - it s clearly everywhere - and also
the interfaces for calling and texting someone.
To explain what the internet is, besides the fact that one
can use it for calling and listening to music, she says:
 When I asked if he knew what actually happens between the device and a
website he visits, he put forth the hypothesis of the existence of some
kind of
When I asked if he knew what actually happens between the device and a
website he visits, he put forth the hypothesis of the existence of some
kind of
 See
See  This post describes how I m using
This post describes how I m using